- Python 内存管理
- python 运行原理
- 字符编码
- len() 获取字符长度
- 格式化输出
- list
- tuple
- dict
- set
- 条件判断
- 循环
- 函数
- 递归
- list数据的截取访问
- 迭代
- 列表生成式
- 生成器(generator)
- 可迭代对象、迭代器与生成器的关系
- map()与reduce()
- 匿名函数
- 装饰器 decorator
- 变量访问权限
- 模块搜索路径
- 类
- 类成员的访问权限
- 继承
- 类型判断
- 获取对象属性或方法
- 类属性
- slots 限制成员的添加
- 使用@property、@xxx.setter
- Python 支持多继承(一个子类可以有多个父类)
- 异常
- 文件IO
- StringIO,BytesIO
- 文件目录操作
- 序列化
- 获取时间
Python 内存管理
一篇讲解的非常好的文档:https://realpython.com/python-memory-management/
一切都是对象
在 Python 中一切都是对象,CPython 解释器中都用一个结构体 pyobject 表示
typedef struct _object {
Py_ssize_t ob_refcnt; // 引用计数机制用于实现垃圾回收
struct _typeobject *ob_type; // 执行一个 Python 中具体的类型
} PyObject;
引用计数
引用计数是计算机编程语言中的一种内存管理技术,是指将资源(可以是对象、内存或磁盘空间等等)的被引用次数保存起来,当被引用次数变为零时就将其释放的过程。使用引用计数技术可以实现自动资源管理的目的。同时引用计数还可以指使用引用计数技术回收未使用资源的垃圾回收算法。
当创建一个对象的实例并在堆上申请内存时,对象的引用计数就为1,在其他对象中需要持有这个对象时,就需要把该对象的引用计数加1,需要释放一个对象时,就将该对象的引用计数减1,直至对象的引用计数为0,对象的内存会被立刻释放。
python 中引用计数增加的情况:
- assignment operator, obj1 = obj2
- argument passing, 函数传参
- appending an object to a list (object’s reference count will be increased), 将对象添加到 list
注意:在函数、类和块之外声明的变量称为全局变量。通常,这样的变量会一直存在到 Python 进程的结束。因此,由全局变量引用的对象的引用计数永远不会下降到0
Python 中引用计数减少的情况:
- 在块内定义的变量(例如,在函数或类中)具有本地作用域(即,它们是块的本地变量)。如果 Python 解释器退出该块,它将销毁在该块中创建的所有引用。
GIL
python 中内存引用计数被多个所引用的对象共享,因此,有可能发生“在同一时刻有两个线程同时访问同一块内存”,引起错误,为了避免该问题,python 引入 GIL 全局解释器锁
python 引用与拷贝
a = [1,2,3] # 创建对象 a, 并开辟内存
b = a # `a is b` will return True. b 只是 a 的引用,没有 copy
a is b判断 a 和 b 是否引用自同一个对象a == b判断 a 和 b 的内容是否一致a is breturn Ture ==>a == breturn True, 反之,不一定成立
Python 中使用 copy 有深拷贝和浅拷贝
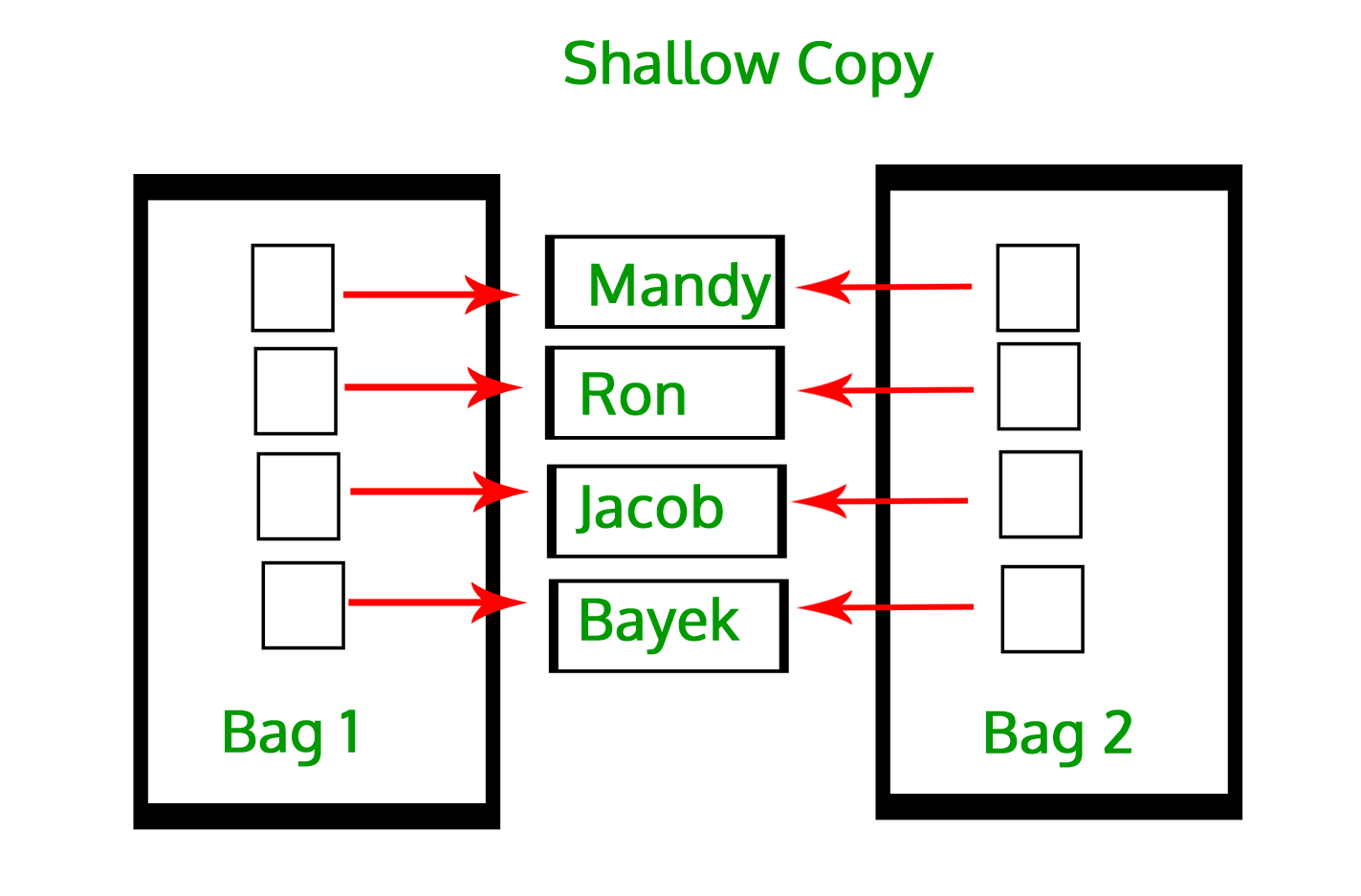
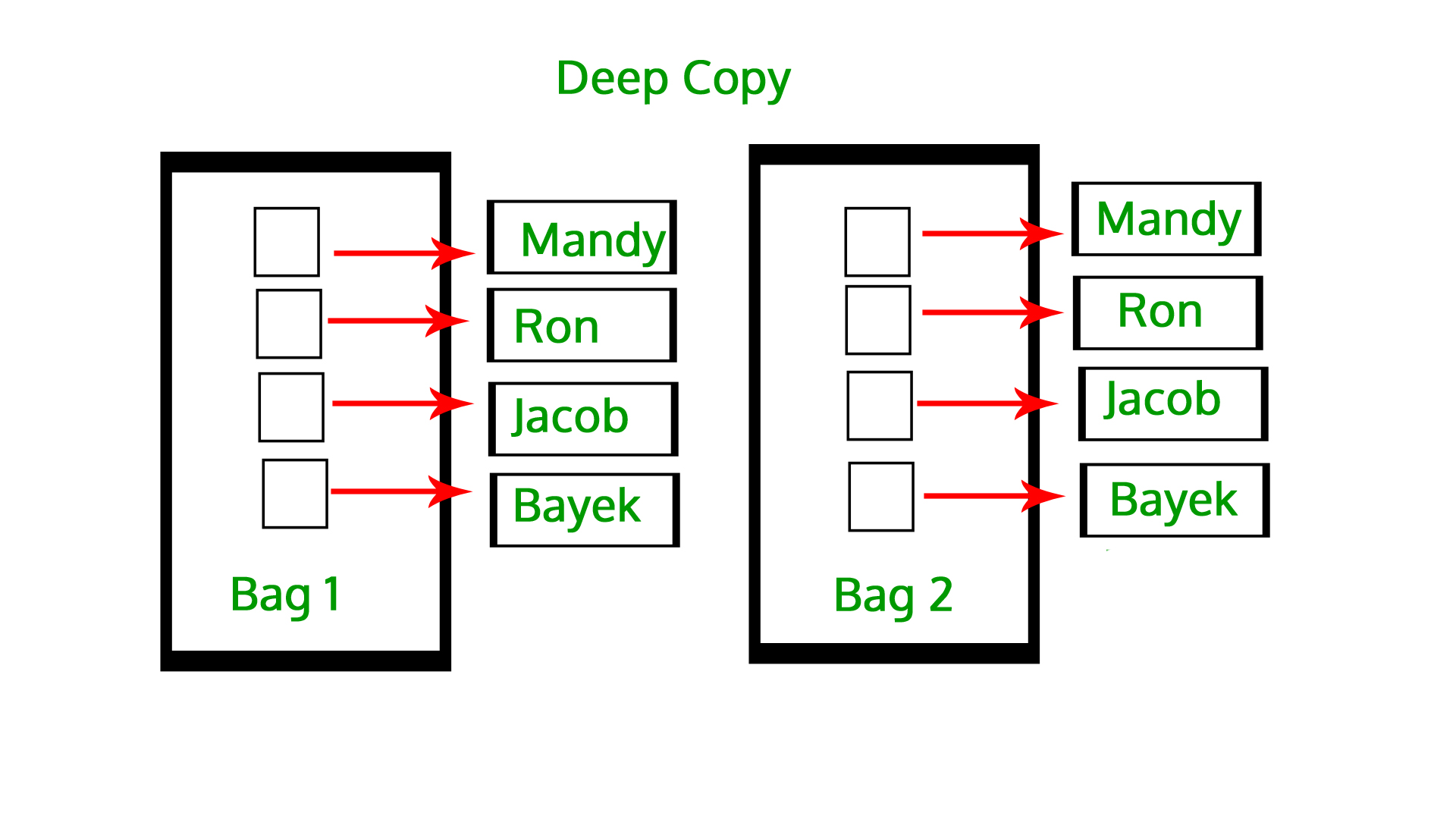
可以使用 python 中 copy 模块进行浅拷贝和深拷贝操作
Inplace vs Standard Operators in Python
python 运行原理
执行 python xxx.py 后,进行的操作:
xxx.py ___解释器___> 字节码 ___虚拟机___> 机器码
字符编码
python 中 str 就是 Unicode 编码的 bytes,显示的时候自动转换为可读字符;bytes 是其它编码的 bytes 序列,以 b’abc\x88’形式创建或显示(能以 ascii 显示的自动转换成对应的 ascii)
python 采用 unicode 编码(内存中每个字符占4个字节),通过 str.encode() 和 bytes.decode() 实现字符的编码和解码。
- bytes.decode() : 其它编码的 bytes 序列 -> str (unicode bytes)
- 编码:str (unicode bytes) -> 其它编码的 bytes
b’xxx’ 代表其他编码的 bytes 数据
源文件中
#-*- coding: utf-8 -*-向python解释器声明文件以utf-8编码
ch = '中国'
bt = ch.encode('utf-8') # b'\xe4\xb8\xad\xe5\x9b\xbd' 默认 encoding='utf-8'
bt.decode('utf-8') # '中国' decode() 默认也是 utf-8
len() 获取字符长度
格式化输出
print(‘Your name is %s, age is %d.’ %(name, age)) # %s 通用
list
类似数组,但其元素类型可不同
- 创建:L=[‘abc’, 123,12.3]
- 访问:L[0] = 123 L[-1] = 5 L[-2] = 5
- 插入 L.insert(i, value)
- 添加 L.append(value)
- 删除
L.pop(i) # 删除第 i 个 L.pop() # 删除最后一个 - 根据内容删除 L.remove(value)
- 长度 len(L)
tuple
定长数组,定义后不可变
- T=(‘a’,’b’,’c’)
- 访问:T[0]
dict
- 初始化:d = {‘aa’: 1, ‘bb’: 2, ‘cc’: 3}
- 访问:d[‘aa’] = 5 d.get(‘a’)
- 是否含有: ‘aa’ in d -删除:d.pop(‘a’)
- 从两个 list 创建 dict
>>> keys = ['a', 'b', 'c'] >>> values = [1, 2, 3] >>> dictionary = dict(zip(keys, values)) >>> print(dictionary) {'a': 1, 'b': 2, 'c': 3}
要保证hash的正确性,作为key的对象就不能变。在Python中,字符串、整数等都是不可变的,因此,可以放心地作为key。而list是可变的,就不能作为key
set
不重复的集合
- 创建: s = set([1,2,3,4])
- 添加和删除:s.add(5), s.remove(3)
-
与或运算:&
set和dict的唯一区别仅在于没有存储对应的value,但是,set的原理和dict一样,所以,同样不可以放入可变对象,因为无法判断两个可变对象是否相等,也就无法保证set内部“不会有重复元素”。
注意:list, set, tuple等都是引用类型,与数值类型不同。
条件判断
if <条件判断1>:
<执行1>
elif <条件判断2>:
<执行2>
elif <条件判断3>:
<执行3>
else:
<执行4>
循环
sum = 0
for x in range(101):
sum = sum + x
print(sum)
函数
python提供内置函数,如abs(), int(). 函数名称实际上是指向函数的引用可以赋值给其它变量(类似于matlab中的函数句柄,C++中的函数指针)
定义函数
def my_abs(x):
if not isinstance(x, (int, float)):
raise TypeError('bad operand type')
if x >= 0:
return x
else:
return -x
定义函数时,需要确定函数名和参数个数;
如果有必要,可以先对参数的数据类型做检查(使用isinstance());
函数体内部可以用return随时返回函数结果;
函数执行完毕也没有return语句时,自动return None;
函数可以同时返回多个值,但其实就是一个tuple;
使用 from file_name import function_name 导入函数;
pass占位符
Python函数在定义的时候,默认参数L的值就被计算出来了,即[],因为默认参数L也是一个变量,它指向对象[],每次调用该函数,如果改变了L的内容,则下次调用时,默认参数的内容就变了,不再是函数定义时的[]了。
对于不变对象来说,调用对象自身的任意方法,也不会改变该对象自身的内容。相反,这些方法会创建新的对象并返回,这样,就保证了不可变对象本身永远是不可变的。str是不可变对象,list是可变对象
为什么要设计str、None这样的不变对象呢?因为不变对象一旦创建,对象内部的数据就不能修改,这样就减少了由于修改数据导致的错误。此外,由于对象不变,多任务环境下同时读取对象不需要加锁,同时读一点问题都没有。我们在编写程序时,如果可以设计一个不变对象,那就尽量设计成不变对象。
函数参数
- 位置参数(依靠位置匹配)
- 默认参数(C++类似)
- 可变参数(可以传入一个或多个参数)
def calc(*numbers):
sum = 0
for n in numbers:
sum = sum + n * n
return sum
定义可变参数和定义一个list或tuple参数相比,仅仅在参数前面加了一个*号。在函数内部,参数numbers接收到的是一个tuple,因此,函数代码完全不变。但是,调用该函数时,可以传入任意个参数,包括0个参数
- 关键字参数(调用参数时指出形参名称)
def person(name, age, **kw): print('name:', name, 'age:', age, 'other:', kw) ------------- person('Bob', 35, city='Beijing') person('Adam', 45, gender='M', job='Engineer') - 命名关键字参数(调用参数时指出形参名称,类似于matlab中的 pair-value)
def person(name, age, *, city, job): print(name, age, city, job) - 参数组合
以上参数可以组合,其定义顺序:必选参数、默认参数、可变参数、命名关键字参数和关键字参数。
递归
使用递归函数的优点是逻辑简单清晰,缺点是过深的调用会导致栈溢出。
针对尾递归优化的语言可以通过尾递归防止栈溢出。尾递归事实上和循环是等价的,没有循环语句的编程语言只能通过尾递归实现循环。
Python标准的解释器没有针对尾递归做优化,任何递归函数都存在栈溢出的问题。
# 汉诺塔递归
def hano(a,b,c,n):
if n==1:
print(a,'->',c) # 当只剩下一个盘子时,直接从源柱搬到目标柱
else:
hano(a,c,b,n-1) # 否则将源柱的n-1个盘子借助源柱搬到中柱
print(a,'->',c) # 再将源柱最后一个盘子直接搬到目标柱
hano(b,a,c,n-1) # 将中柱的n-1个盘子借助源柱搬到目标柱
return
hano('A','B','C',10)
list数据的截取访问
l=list(range(100))
l[:3]
l[1:3]
l[-2:]
l[-4:-2]
l[:]
l[1:11:2]
l[::5]
注意:
不包含end_index
下标从0开始
也适用于str,tuple
迭代
可迭代的对象有:list, tuple, dict, str, …
l=list(range(100))
for n in l:
print(n)
判断是否可迭代
>>> from collections import Iterable
>>> isinstance('abc', Iterable) # str是否可迭代
True
>>> isinstance([1,2,3], Iterable) # list是否可迭代
True
>>> isinstance(123, Iterable) # 整数是否可迭代
False
列表生成式
用于创建list
import os
a = [d for d in os.listdir('.')]
print(a)
生成器(generator)
随用随生成的list
g = (x * x for x in range(10))
print(next(g))
for n in g:
print(n)
可迭代对象、迭代器与生成器的关系
- 可迭代对象包含迭代器, 容器(list, dict, set, etc) 和文件流等
- 生成器是迭代器
- 可迭代对象必须实现
__iter__或__getitem__ - 迭代器必须实现
__iter__和__next__ - 迭代器可以使用 next(iterator)
- 通过 iter(iterable) 函数可以将可迭代对象转换成迭代器
- 可迭代对象和迭代器都可以使用
for .. in ..
map()与reduce()
map()函数接收两个参数,一个是函数,一个是Iterable,map将传入的函数依次作用到序列的每个元素,并把结果作为新的Iterator返回。
reduce()把一个函数作用在一个序列[x1, x2, x3, …]上,这个函数必须接收两个参数,reduce把结果继续和序列的下一个元素做累积计算,
reduce(f, [x1, x2, x3, x4]) = f(f(f(x1, x2), x3), x4)
b=list(map(str, [1, 2, 3, 4, 5, 6, 7, 8, 9])) # str() 将参数转成字符串
print(b)
# 将str 转 int 函数(使用 dict, map, reduce)
from functools import reduce
DIGITS = {'0': 0, '1': 1, '2': 2, '3': 3, '4': 4, '5': 5, '6': 6, '7': 7, '8': 8, '9': 9}
def str2int(s):
def fn(x, y):
return x * 10 + y
def char2num(s):
return DIGITS[s]
return reduce(fn, map(char2num, s))
filter() 筛选器
def is_odd(n):
return n % 2 == 1
list(filter(is_odd, [1, 2, 4, 5, 6, 9, 10, 15]))
sorted 排序
sorted([36, 5, -12, 9, -21], key=abs)
sorted(['bob', 'about', 'Zoo', 'Credit'], key=str.lower, reverse=True)
返回函数
def lazy_sum(*args):
def sum():
ax = 0
for n in args:
ax = ax + n
return ax
return sum
当我们调用lazy_sum()时,返回的并不是求和结果,而是求和函数:
>>> f = lazy_sum(1, 3, 5, 7, 9)
>>> f
<function lazy_sum.<locals>.sum at 0x101c6ed90>
调用函数f时,才真正计算求和的结果:
>>> f()
25
在这个例子中,我们在函数lazy_sum中又定义了函数sum,并且,内部函数sum可以引用外部函数lazy_sum的参数和局部变量,当lazy_sum返回函数sum时,相关参数和变量都保存在返回的函数中,这种称为“闭包(Closure)”的程序结构拥有极大的威力。
匿名函数
lambda args : expresion
list(map(lambda x: x * x, [1, 2, 3, 4, 5, 6, 7, 8, 9]))
f = lambda x: x * x
装饰器 decorator
实现对一个函数的二次包装,同名包装
def log(func):
def wrapper(*args, **kw):
print('call %s():' % func.__name__)
return func(*args, **kw)
return wrapper
@log
def now():
print('2015-3-25')
调用now()函数,不仅会运行now()函数本身,还会在运行now()函数前打印一行日志:
>>> now()
call now():
2015-3-25
把@log放到now()函数的定义处,相当于执行了语句: now = log(now)
由于log()是一个decorator,返回一个函数,所以,原来的now()函数仍然存在,只是现在同名的now变量指向了新的函数,于是调用now()将执行新函数,即在log()函数中返回的wrapper()函数。
补充:函数的 __name__ 属性,func.__name__ 获取函数名称
模块文件格式
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
' a test module '
__author__ = 'Michael Liao'
import sys
def test():
args = sys.argv
if len(args)==1:
print('Hello, world!')
elif len(args)==2:
print('Hello, %s!' % args[1])
else:
print('Too many arguments!')
if __name__=='__main__':
test()]
第1行和第2行是标准注释,第1行注释可以让这个hello.py文件直接在Unix/Linux/Mac上运行,第2行注释表示.py文件本身使用标准UTF-8编码; 第4行是一个字符串,表示模块的文档注释,任何模块代码的第一个字符串都被视为模块的文档注释;
第6行使用__author__变量把作者写进去,这样当你公开源代码后别人就可以瞻仰你的大名。
import sys 导入sys模块后,我们就有了变量sys指向该模块,利用sys这个变量,就可以访问sys模块的所有功能。
sys模块有一个argv变量,用list存储了命令行的所有参数。argv至少有一个元素,因为第一个参数永远是该.py文件的名称,例如:
运行python3 hello.py获得的sys.argv就是[‘hello.py’];
运行python3 hello.py Michael获得的sys.argv就是[‘hello.py’, ‘Michael]。
最后,注意到这两行代码:
if __name__=='__main__':
test()
当我们在命令行运行hello模块文件时,Python解释器把一个特殊变量__name__置为__main__,而如果在其他地方导入该hello模块时,if判断将失败,因此,这种if测试可以让一个模块通过命令行运行时执行一些额外的代码,最常见的就是运行测试。
变量访问权限
正常的函数和变量名是公开的(public),可以被直接引用,比如:abc,x123,PI等;
类似__xxx__这样的变量是特殊变量,可以被直接引用,但是有特殊用途,比如上面的__author__,__name__就是特殊变量,hello模块定义的文档注释也可以用特殊变量__doc__访问,我们自己的变量一般不要用这种变量名;
类似_xxx和__xxx这样的函数或变量就是非公开的(private),不应该被直接引用,比如_abc,__abc等;
之所以我们说,private函数和变量“不应该”被直接引用,而不是“不能”被直接引用,是因为Python并没有一种方法可以完全限制访问private函数或变量,但是,从编程习惯上不应该引用private函数或变量。
def _private_1(name):
return 'Hello, %s' % name
def _private_2(name):
return 'Hi, %s' % name
def greeting(name):
if len(name) > 3:
return _private_1(name)
else:
return _private_2(name)
模块搜索路径
当执行 import xxx时, Python解释器会搜索当前目录、所有已安装的内置模块和第三方模块,搜索路径存放在sys模块的path变量中。
添加自己的搜索目录两种方法:1. 使用 sys.path.append(‘xxx’), 类似与MATLAB addpath(),程序结束失效;2. 设置 PYTHONPATH 类似 Java中的 CLASSPATH
类
class Student(object):
def __init__(self, name, score):
self.name = name
self.score = score
def print_score(self):
print('%s: %s' % (self.name, self.score))
----------------------------------------------------
s1 = Student('Mike', 90)
s1.print()
和静态语言不同,Python允许对实例变量绑定任何数据,也就是说,对于两个实例变量,虽然它们都是同一个类的不同实例,但拥有的变量名称都可能不同.
类成员的访问权限
class Student(object):
def __init__(self, name, score):
self.__name = name
self.__score = score
def print_score(self):
print('%s: %s' % (self.__name, self.__score))
双下划线开头的变量为私有变量。有些时候,你会看到以一个下划线开头的实例变量名,比如_name,这样的实例变量外部是可以访问的,但是,按照约定俗成的规定,当你看到这样的变量时,意思就是,“虽然我可以被访问,但是,请把我视为私有变量,不要随意访问”。
__var__: 特殊用途
__var: 真私有
_var: 假私有
继承
class Man(object):
def __init__(self):
pass
def print(self):
print('Man')
class Student(Man):
def __init__(self, name, age):
self.__name = name
self.__age = age
def print(self):
print('name is %s, age is %s.' %(self.__name, self.__age))
def test():
print('test')
m = Man()
s1 = Student('Make',12)
s1.score = 90
s1.print()
m.print()
是什么类型就调用该类型的方法,子类的方法会覆盖父类的方法。
类型判断
type() 返回基本类型、函数、对象引用的类型
a=123
print(type(a) == int)
class Man(object):
def __init__(self):
pass
def print(self):
print('Man')
m = Man()
print(type(m) == Man)
print(type(abs))
import types
print(type(abs) == types.FunctionType) # 判断是否是函数类型
isinstance() 判断某一实例是否是某一类型(基本类型、引用类型)
isinstance('123', str)
import types
isinstance(abs, types.BuiltinFunctionType)
isinstance(m, Man)
isinstance([1,2,3], (list, tuple))
总是优先使用isinstance()判断类型,可以将指定类型及其子类“一网打尽”。
获取对象属性或方法
dir() 获取全部属性和方法,构成 list
hasattr() 类似MATLAB中的 isproperty()
getattr() 类似MATLAB中的 get()
setattr() 类似MATLAB中的 set()
del obj.xxx 删除实例属性
l = dir('123')
for i in l:
print(i)
类属性
class Man(object):
place = 'beijing'
def __init__(self):
pass
def print(self):
print('Man')
class Student(Man):
def __init__(self, name, age):
self.__name = name
self.__age = age
def print(self):
print('name is %s, age is %s.' %(self.__name, self.__age))
s = Student('hh', 12)
print(s.place)
类似于“静态成员变量”
注意: Python 属于动态语言,对象或类测成员可以动态添加。
slots 限制成员的添加
class Animal(object):
__slots__ = ('name', 'age')
def __init__(self):
print('Animal!')
class Dog(Animal):
__slots__ = ()
def __init__(self):
print('Dog!')
a = Animal()
a.name = 'aa'
a.age = 'bb'
d = Dog()
d.name = 'beijing'
注意:
在父类中定义slots,在子类中没有定义,则不对子类起作用;
在父类中定义slots,在子类中也有定义,则子类实例允许定义的属性就是自身的__slots__加上父类的__slots__。
使用@property、@xxx.setter
@property 作用:将get方法当成属性来用;
@xxx.setter 作用:将set方法当成属性来用。
既实现了数据的隐藏,也简化了调用方式(避免直接调用get和set方法,而是直接引用属性即可)。
# 不使用@property
class Student(object):
def __init__(self):
self.__name = 'abc'
self.__score = 0
def name1(self):
return self.__name
s = Student()
print(s.name1())
# 使用@property
class Student(object):
def __init__(self):
self.__name = 'abc'
self.__score = 0
@property
def name1(self):
return self.__name
s = Student()
print(s.name1) # 在名为name1的get方法定义时加上@property,就可以当成属性来用,一般该方法名与类内部属性名相同
class Student(object):
def __init__(self):
self.__name = 'abc'
self.__score = 0
@property
def name(self):
return self.__name
@name.setter
def name(self, value):
if isinstance(value, str):
self.__name = value
else:
print('cannot set value!')
return None
s = Student()
print(s.name)
s.name = 111 # 此处自动调用set方法
print(s.name)
Python 支持多继承(一个子类可以有多个父类)
MixIn 设计模式
定制类
在类中实现一些特殊函数以丰富类的功能。
__str__:print(obj) 时调用
__repr__:调试显示
__iter__/__next__:for 循环迭代
__getitem__:下标索引
__getattr__:当访问对象不存在的属性时调用
__call__:obj() 调用
异常
# 捕获异常
# err_logging.py
import logging
def foo(s):
return 10 / int(s)
def bar(s):
return foo(s) * 2
def main():
try:
bar('0')
except Exception as e:
logging.exception(e)
main()
print('END')
# 自定义异常类型
# err_raise.py
class FooError(ValueError):
pass
def foo(s):
n = int(s)
if n==0:
raise FooError('invalid value: %s' % s)
return 10 / n
foo('0')
# 捕获异常,再次抛出异常
# err_reraise.py
def foo(s):
n = int(s)
if n==0:
raise ValueError('invalid value: %s' % s)
return 10 / n
def bar():
try:
foo('0')
except ValueError as e:
print('ValueError!')
raise
bar()
文件IO
文件读取方法:
read()
readline()
readlines()
文件写入
write()
example
# 文本文件读取,默认utf-8编码
try:
f = open('/path/to/file', 'r')
print(f.read())
finally:
if f:
f.close()
# 读取其它其他编码的文本
>>> f = open('/Users/michael/gbk.txt', 'r', encoding='gbk')
>>> f.read()
'测试'
# 二进制读取
>>> f = open('/Users/michael/test.jpg', 'rb')
>>> f.read()
b'\xff\xd8\xff\xe1\x00\x18Exif\x00\x00...' # 十六进制表示的字节
调用read()会一次性读取文件的全部内容,如果文件有10G,内存就爆了,所以,要保险起见,可以反复调用read(size)方法,每次最多读取size个字节的内容。另外,调用readline()可以每次读取一行内容,调用readlines()一次读取所有内容并按行返回list。因此,要根据需要决定怎么调用。
如果文件很小,read()一次性读取最方便;如果不能确定文件大小,反复调用read(size)比较保险;如果是配置文件,调用readlines()最方便.
像open()函数返回的这种有个read()方法的对象,在Python中统称为file-like Object。除了file外,还可以是内存的字节流,网络流,自定义流等等。file-like Object不要求从特定类继承,只要写个read()方法就行。StringIO就是在内存中创建的file-like Object,常用作临时缓冲。
StringIO,BytesIO
>>> from io import StringIO
>>> f = StringIO()
>>> f.write('hello')
5
>>> f.write(' ')
1
>>> f.write('world!')
6
>>> print(f.getvalue())
hello world!
>>> from io import StringIO
>>> f = StringIO('Hello!\nHi!\nGoodbye!')
>>> while True:
... s = f.readline()
... if s == '':
... break
... print(s.strip())
...
Hello!
Hi!
Goodbye!
>>> from io import BytesIO
>>> f = BytesIO()
>>> f.write('中文'.encode('utf-8'))
6
>>> print(f.getvalue())
b'\xe4\xb8\xad\xe6\x96\x87'
>>> from io import BytesIO
>>> f = BytesIO(b'\xe4\xb8\xad\xe6\x96\x87')
>>> f.read()
b'\xe4\xb8\xad\xe6\x96\x87'
文件目录操作
相关函数在 os, os.path 中.
序列化
如果我们要在不同的编程语言之间传递对象,就必须把对象序列化为标准格式,比如XML,但更好的方法是序列化为JSON,因为JSON表示出来就是一个字符串,可以被所有语言读取,也可以方便地存储到磁盘或者通过网络传输。JSON不仅是标准格式,并且比XML更快,而且可以直接在Web页面中读取,非常方便。JSON表示的对象就是标准的JavaScript语言的对象
JSON data encoding:
str = json.dumps(data),将数据格式化成字符串
json.dump(data, out),将数据保存到输出流o(file-like object)
JSON data decoding:
json.loads(str),从 JSON 编码的字符串解析数据到内存
json.load(in),从JSON编码的输入流解析数据到内存
默认支持的类型
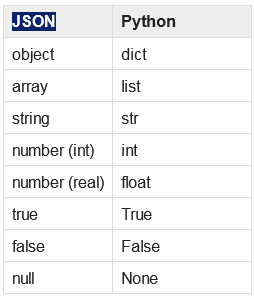
序列化自定义类型
def student2dict(std):
return {
'name': std.name,
'age': std.age,
'score': std.score
}
>>> print(json.dumps(s, default=student2dict))
{"age": 20, "name": "Bob", "score": 88}
可选参数default就是把任意一个对象变成一个可序列为JSON的对象,我们只需要为Student专门写一个转换函数,再把函数传进去即可。
获取时间
import time
time.strftime('%Y%m%d-%H-%M', time.localtime()) # '20190916-15-27'
time.strftime('%Y%m%d-%H:%M', time.gmtime()) # '20190916-07:27' UTC
>>> import datetime
>>> datetime.datetime.now()
datetime.datetime(2009, 1, 6, 15, 8, 24, 78915)