引言
半监督学习(semi-supervised learning)是指手头上有一部分带标签的数据,还有很大一部分没有标签的数据,现在要利用这些数据,尽可能学习到有用的信息。
根据 unlabeled 数据是否是测试集,分为两类:
- Transductive learning: unlabeled 数据是测试集
- Inductive learning: unlabeled 数据不是测试集
生成模型中的半监督学习
(Semi-Supervised Learning for Generative Model)

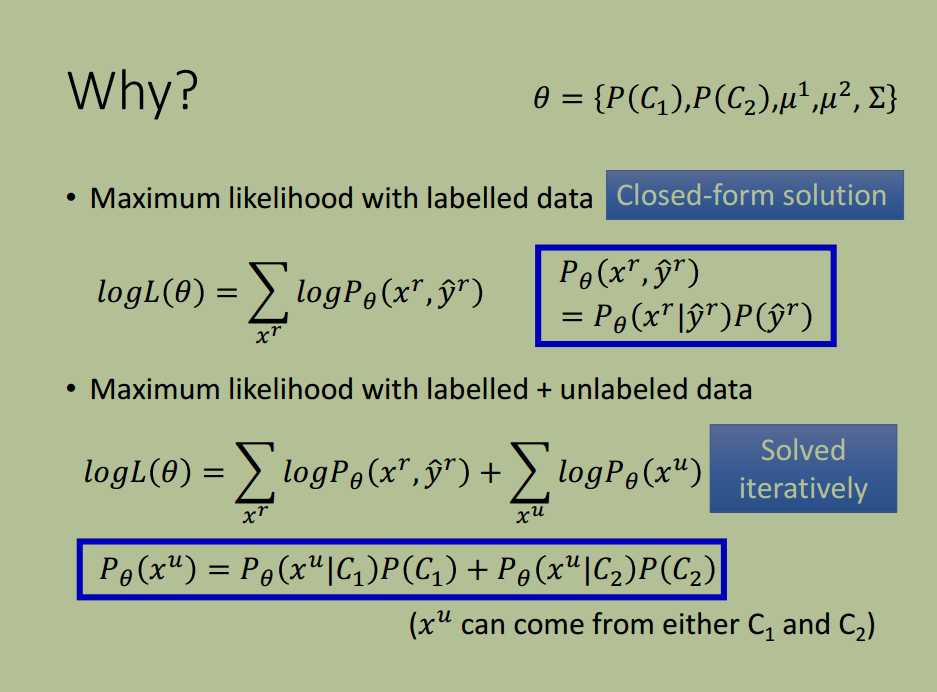
补充:关于似然(likelihood)的理解
一个随机过程有状态空间和参数空间,$P(x; \theta)$ 即可以称为概率,也可以称为似然。当称为概率时,我们关注的是状态空间,当称为似然时,关注的是参数空间。
概率(密度)表达给定下样本随机向量
的可能性,而似然表达了给定样本
下参数
(相对于另外的参数
)为真实值的可能性。我们总是对随机变量的取值谈概率,而在非贝叶斯统计的角度下,参数是一个实数而非随机变量,所以我们一般不谈一个参数的概率。
似然 = 样本的联合概率密度,即
边界低密度假设
(Low-density Separation)
“非黑即白”
边界低密度假设:两个类别交界处样本分布稀疏
利用该假设有下面两种应用
Self-training
应用 self-training 到分类问题

基于熵的正则化
(Entropy-based Regularization)
loss 添加正则项,使得 unlabeled 数据预测的类别分布不均匀。

平滑度假设
(Smoothness Assumption)
“近朱者赤,近墨者黑”
相似的 $x$ 具有相同的 $\hat{y}$
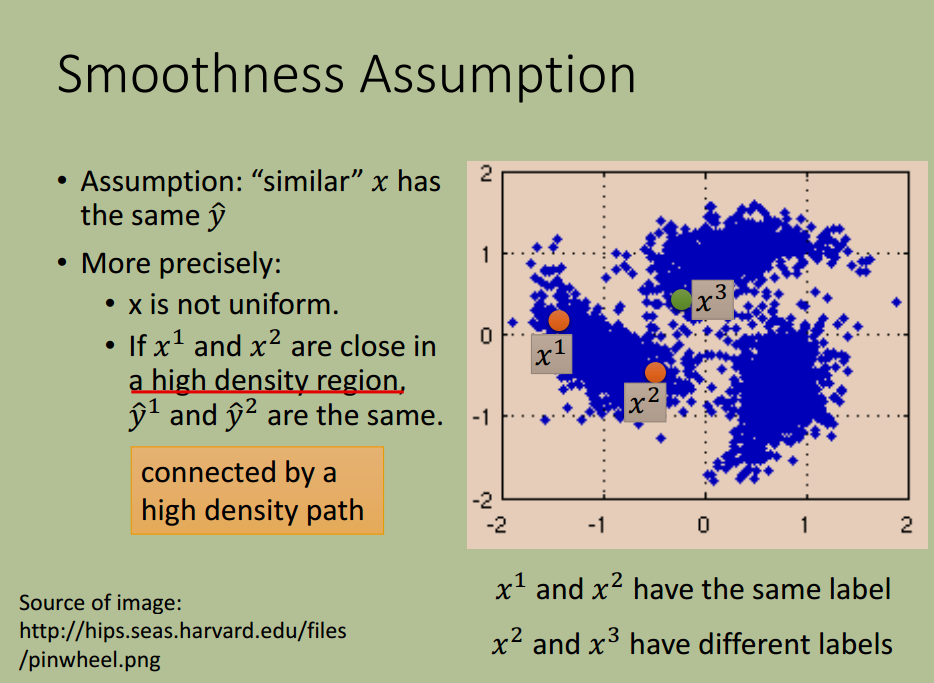
该假设的应用如下
聚类
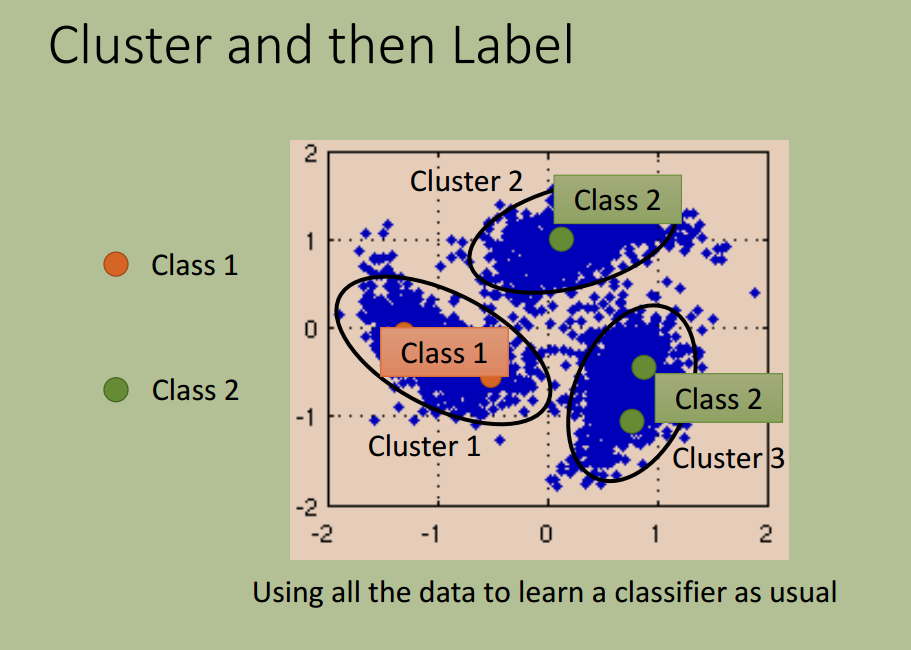
值得指出的是,对于图像不容易直接聚类,可以先采用 deep auto-encoder
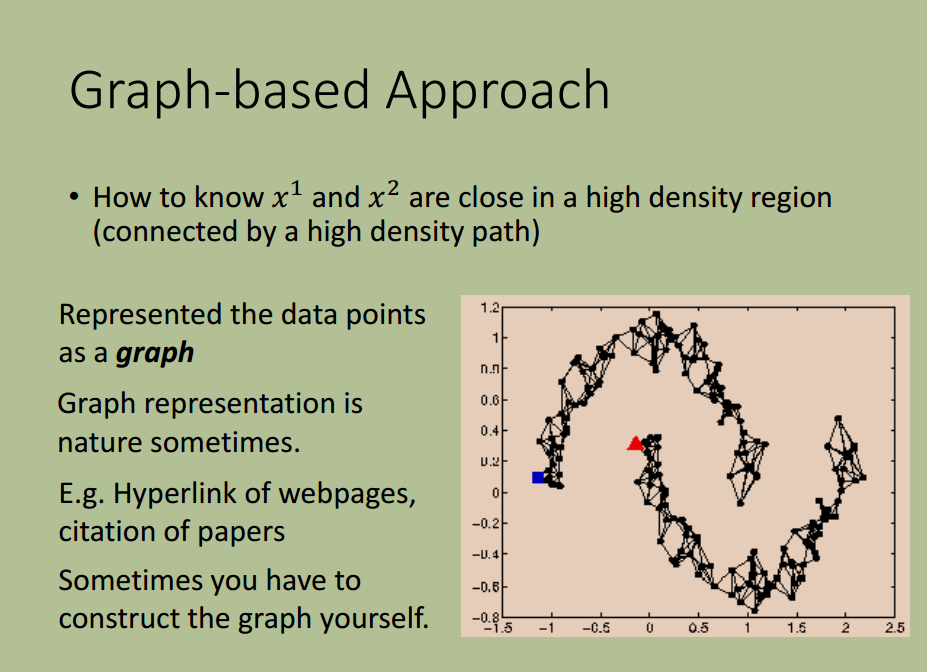
基于图的方法

Better Representation
迁移学习中的属性表示