学习资料
GAN 基础
GAN 的组成
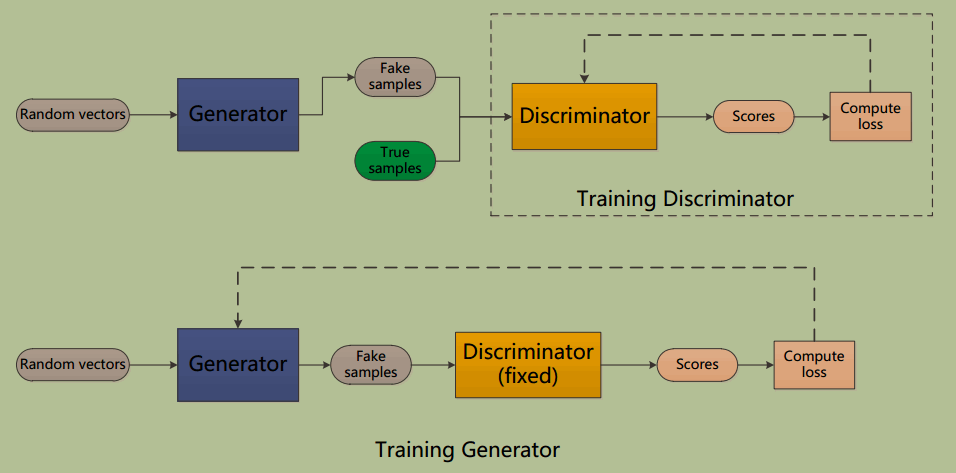
GAN 有两个部分组成:Generator 和 Discriminator,本质上是两个独立的 Network,在用的时候我们往往只用 Generator,而 Discriminator 是在训练中帮助提升 Generator 性能(陪练角色)
- Generator
- 输入:一个随机 vector(服从高斯分布或均匀分布等)
- 输出:期望输出的 sample(比如图片或句子等)
- Discriminator
- 输入:一个 sample
- 输出:对应 sample 为真的概率
例子利用 GAN 生成二次元头像:
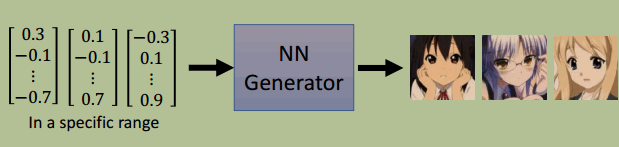
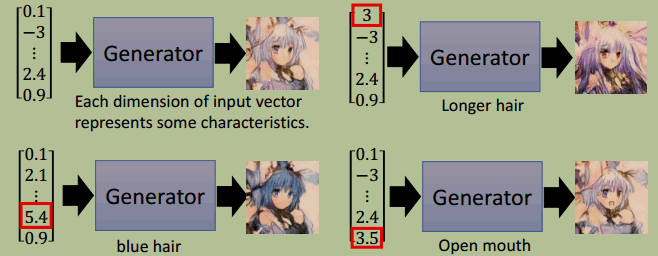
值得注意的是,我们可以操纵输入的 vector,得到 vector 某一维与 sample 某个特征的关系,比如:
GAN 训练算法

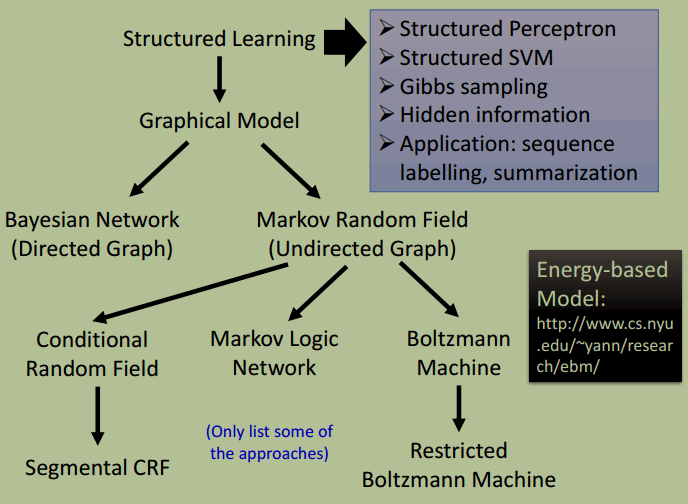
Structured Learning
机器学习是解决这样一个问题:找出一个函数 $f$
- 回归问题:输出一个 scalar
- 分类问题:输出一个 class probability distribution
- 结构化学习或预测:输出一个句子、矩阵、图、树,…(内部各个元素之间有依赖关系)
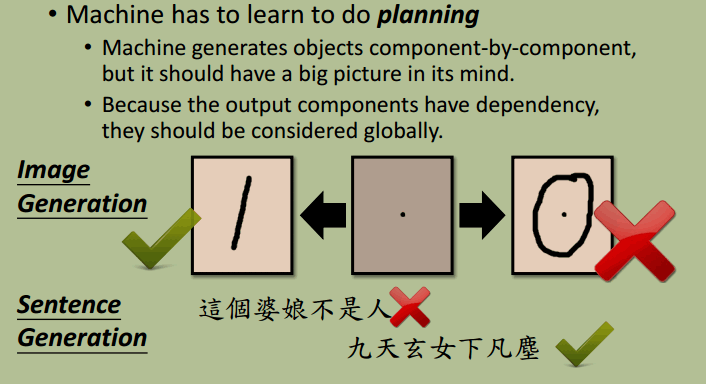
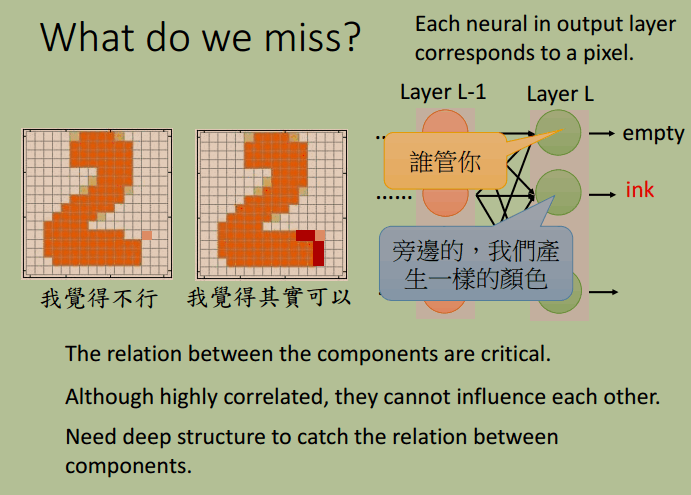
为何结构化学习具有挑战性?
- 从 One-shot/Zero-shot Learning 理解,在训练集中几乎没有完全重合的样本
- 模型必须学习到“大局观”,学习输出各个元素之间的关系。
单独用 Generator 作生成
通过 GAN 的训练算法看出,Generator 的训练必须配合 Discriminator,那么 Generator 能否自己完成 GAN 的工作呢?虽然具有挑战性,但是仍然是可以的,可以利用 Auto-Encoder 的方法,比如 VAE, 问题是它也不容易学习到结构化信息
单独用 Discriminator 作生成
Discriminator 能否自己完成 GAN 的工作呢?答案也是可以的
- 在特征空间随机产生 samples, 交给 Discriminator 判断,将得分高的作为输出
- Discriminator 可以采用迭代式训练方式



总之,只有配合 Generator 和 Discriminator 才能更好的完成生成任务
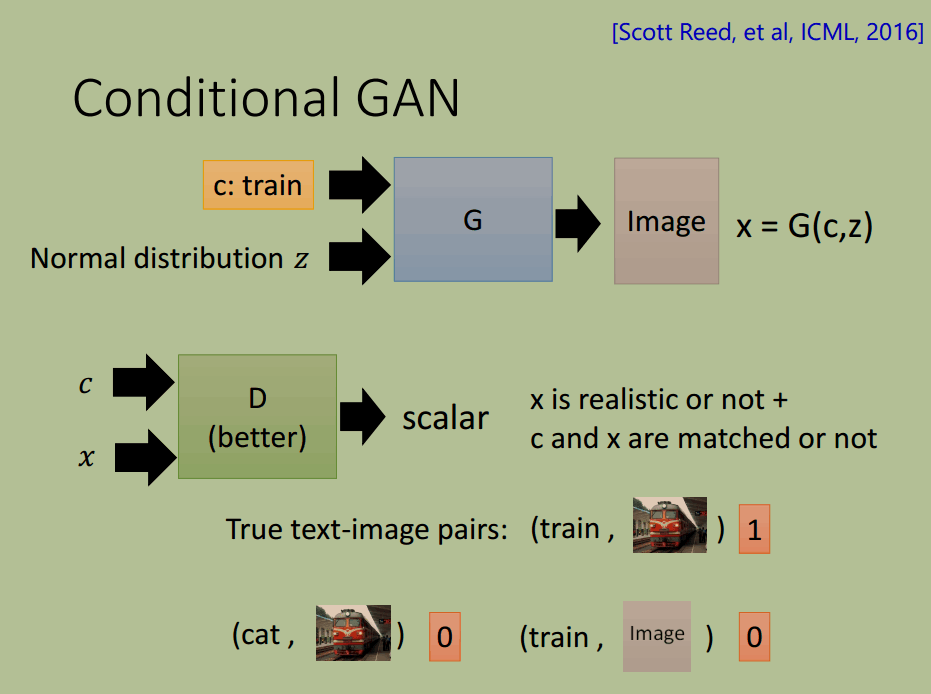
Conditional GAN
上面的 GAN 模型只接收一个随机向量,生成对应的图片,但是我们无法通过改变输入来获得期望的输出,比如我们的模型可以生成各种各样的二次元人物图像,但是当我们想生成诸如“长头发”的图片时,却无法实现。
再比如文字生成图片的问题,模型输入“火车”,返回火车的图片,但是每次的结果不能完全一样。这个任务如果用监督学习,则输入“火车”,输出为各式各样火车图片的平均图像,无法完成。
条件 GAN 可以解决上面这些问题。
训练算法

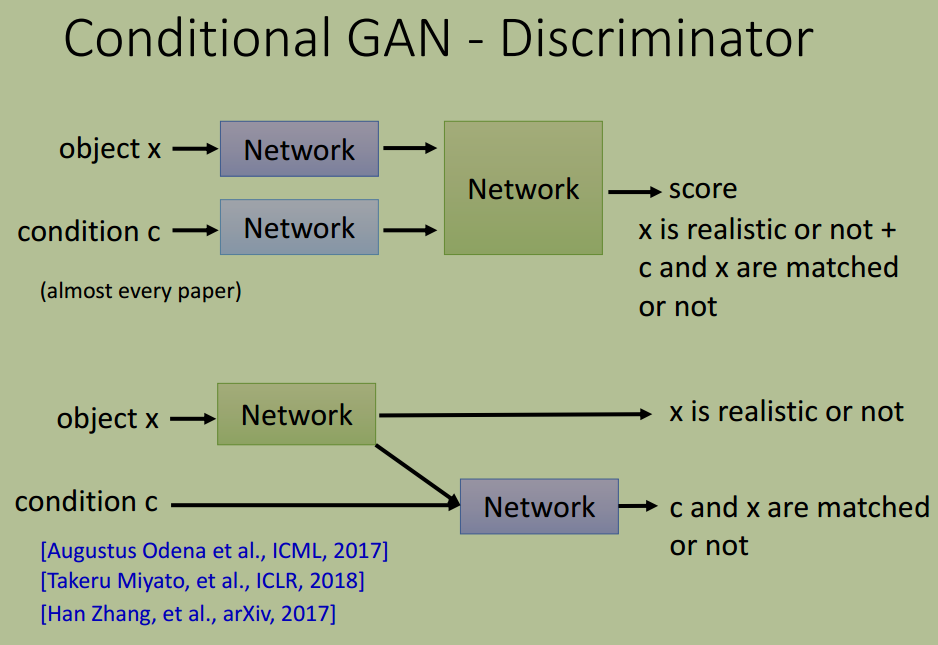
Discriminator 架构
条件 GAN 的 Discriminator 常见的两种架构:
- 单网络
- 双网络
相关应用
- Text-to-Image
- Image-to-Image
- Video Generation
- Speech Enhancement
Unsupervised Conditional Generation
上面介绍的 Conditional GAN 是有监督的,比如产生“长头发”和“短头发”的二次元人物图片,需要事先标注头发长短的标签,在计算 score 时利用标签信息。
现在假设要作风格迁移,将一幅照片变成梵高画作,实际上是 Image-to-Image 问题,但是,我们手头上没有这样一一对应的图像对,只有一堆是照片,另一堆是梵高画作,现在要模型“看过”这堆梵高画作后,将照片变成对应的梵高画作。
实现这个任务有两个方法:
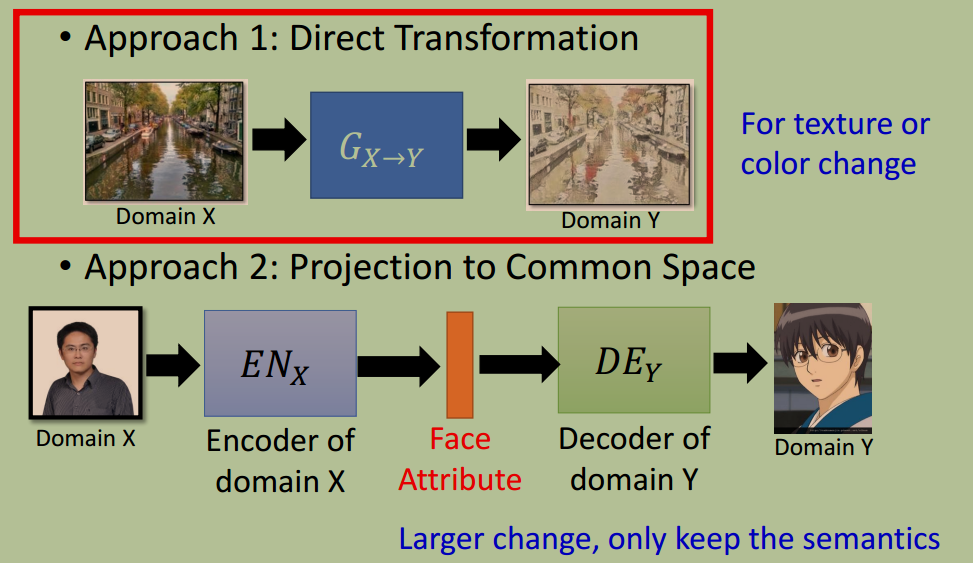
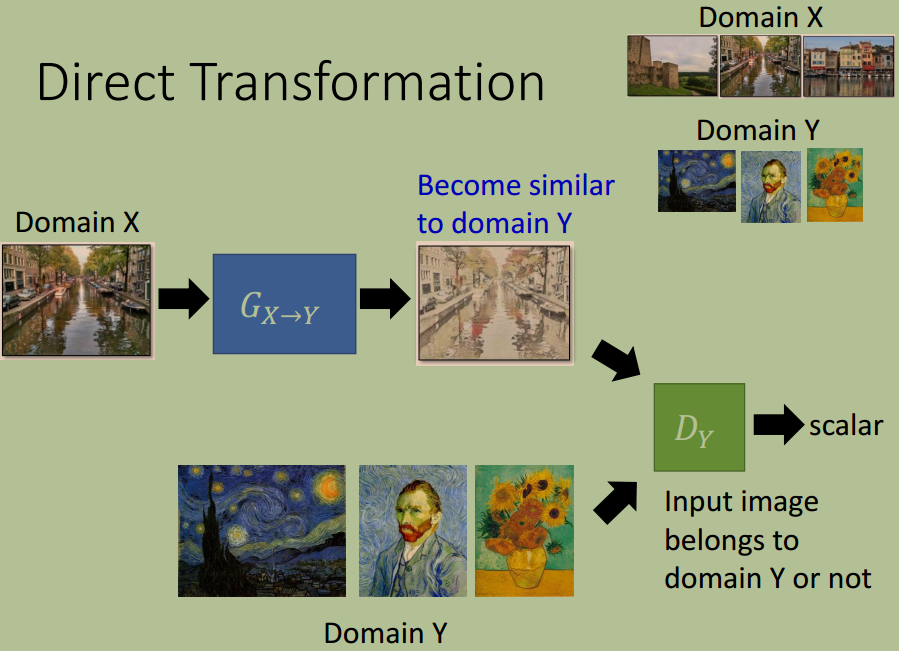
方法 1:直接变换
直接变换的方法是训练一个 Generator,直接完成风格变换。
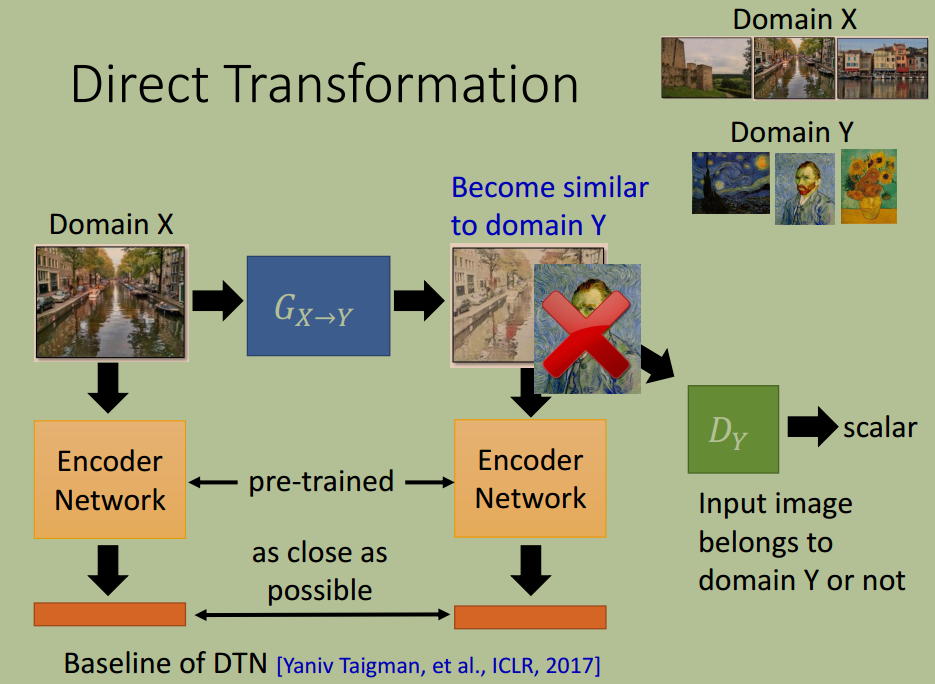
与普通的 GAN 类似,该 Generator 的训练必须辅以一个 Discriminator,该 Discriminator 的作用是判断一幅画是否是梵高画作。在 Generator 层数较浅时,这样做可行,但是层数过深,Generator 可能会使得输入输出两幅图片差异多大。因此,当层数较深时,必须对输出施加约束
对输入输出分别作 encode, 然后使得它们尽可能相似
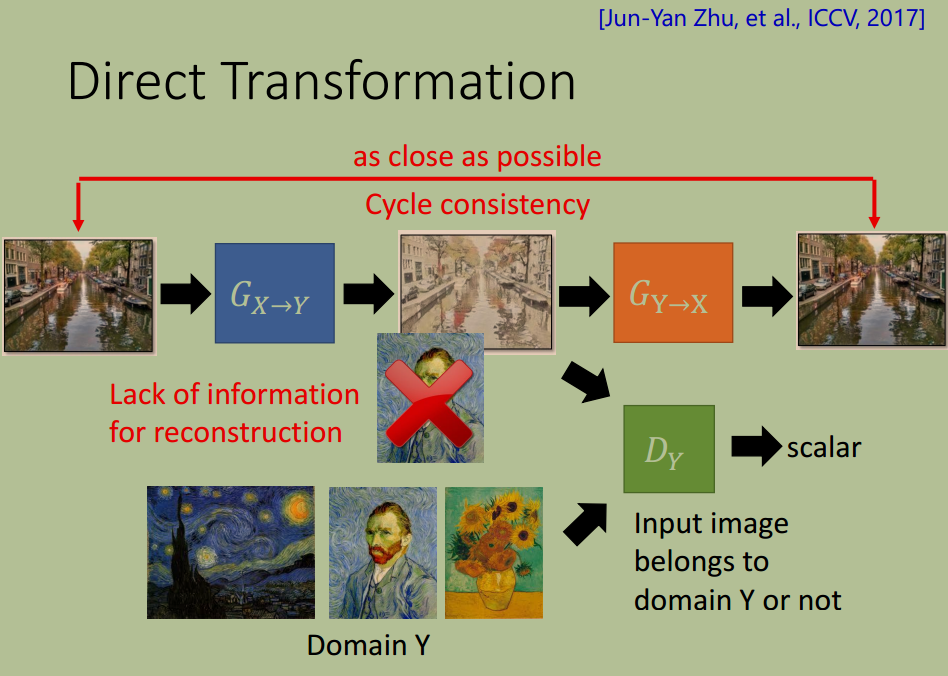
另一种是使用 CycleGAN, 它使用两个 Generator $G_{X \rightarrow Y}$ 和 $G_{Y \rightarrow X}$ 保证循环一致性( Cycle Consistency)
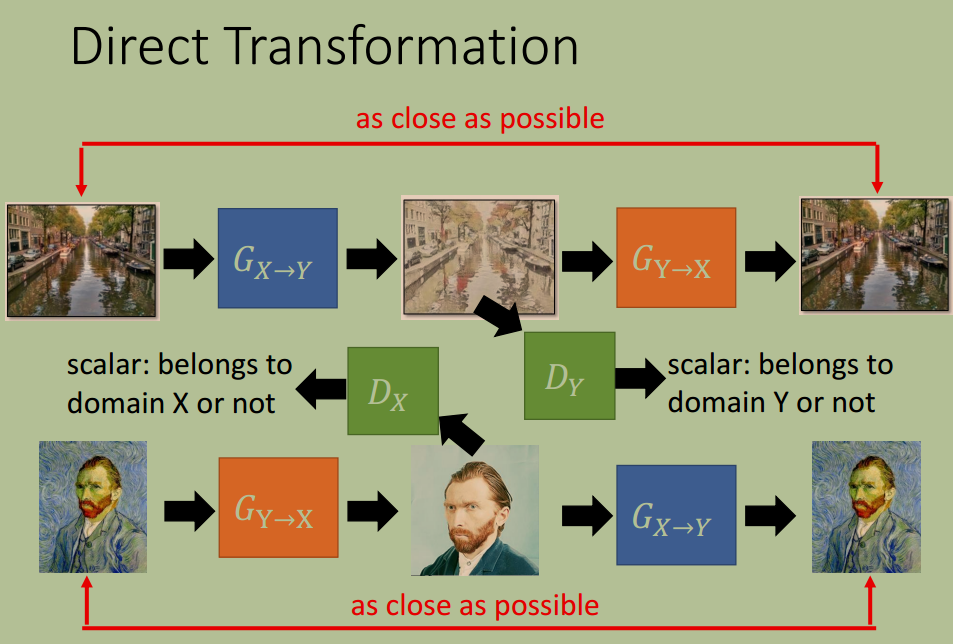
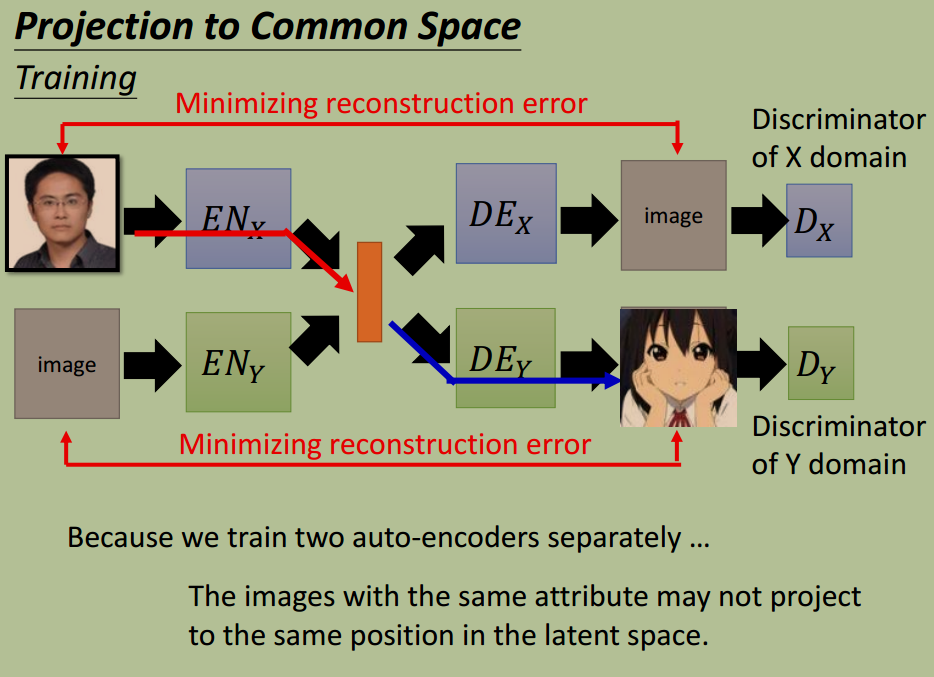
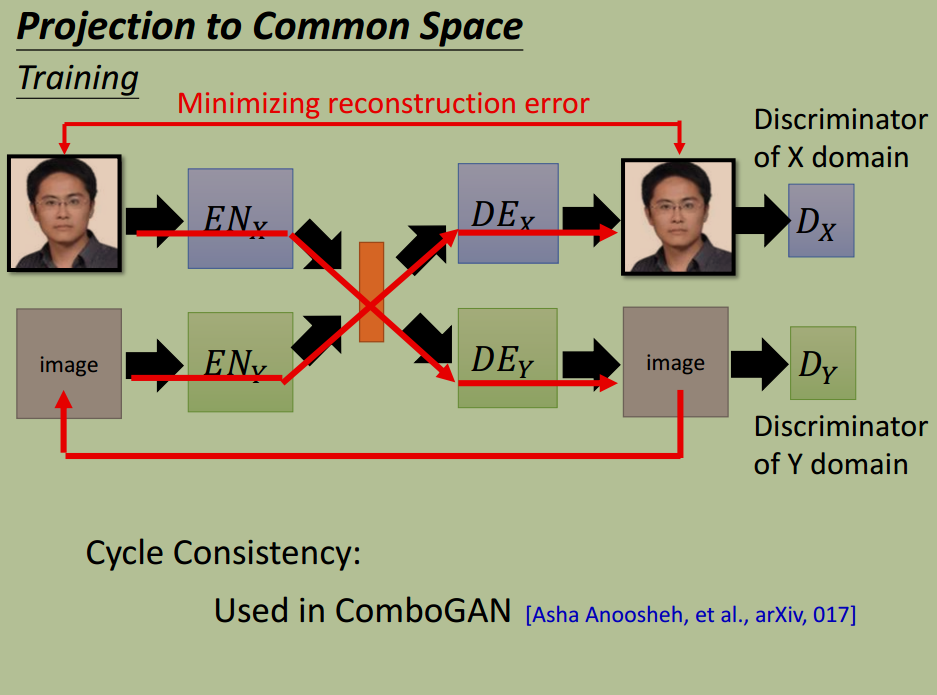
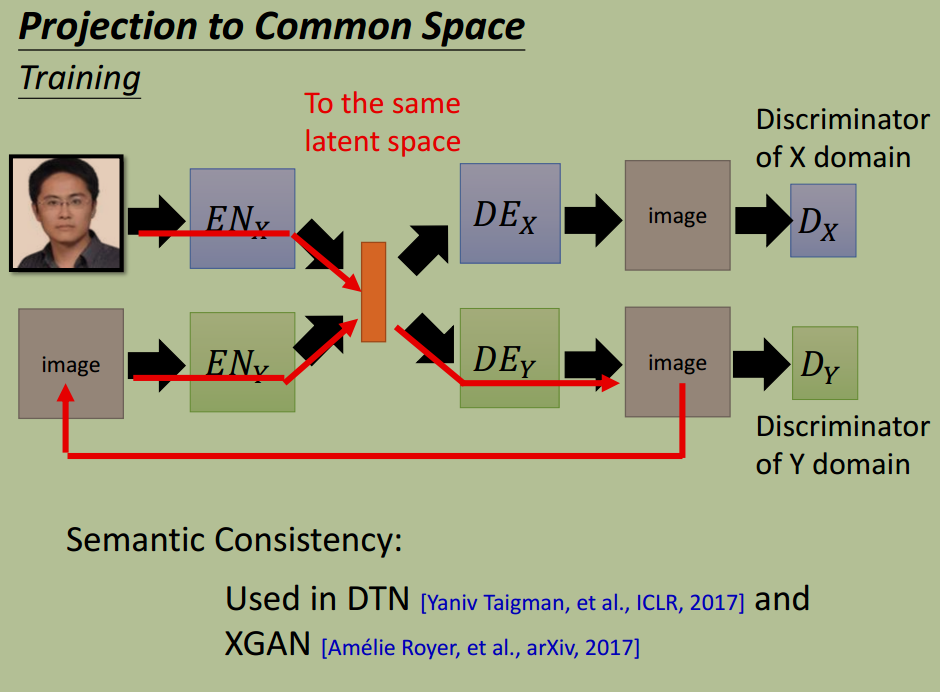
方法 2:投影到共享的特征空间
投影到同一个特征空间,保证同一特征投影到同一个维度上
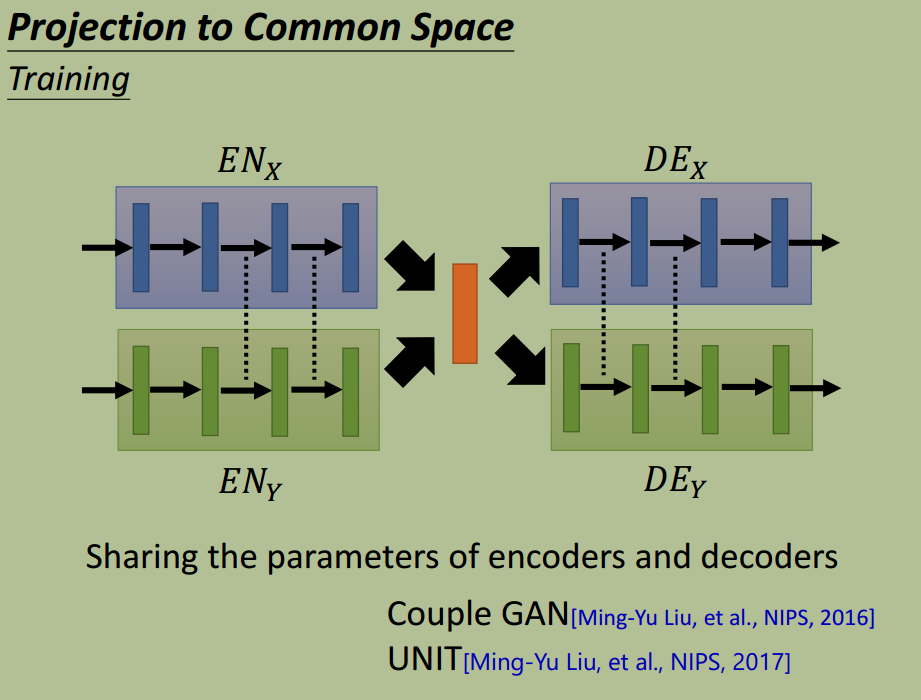
参数绑定,
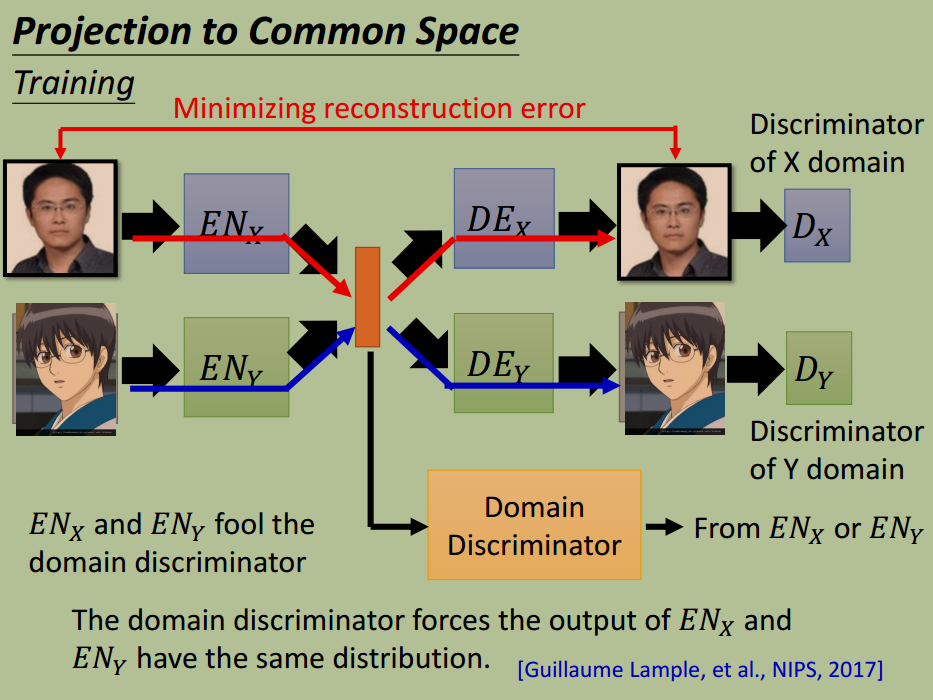
引入 Domain Discriminator,
Cycle Consistency,
Semantic Consistency,
相关应用
- 图片风格迁移
- 声音转换
对比 GAN、条件 GAN、和无监督条件 GAN(以图片生成为例)
- GAN 目的是生成更真实的图片
- 条件 GAN 目的是有条件的生成更真实的图片
- 无监督条件 GAN 目的是不利用标签有条件的生成更真实的图片
示例
基于 mnist 数据集,利用 GAN 生成手写数字
下面是隐变量维度设置成 2 训练模型,然后在 latent space 等间隔采样生成的图片。
