基本概念
两个主体
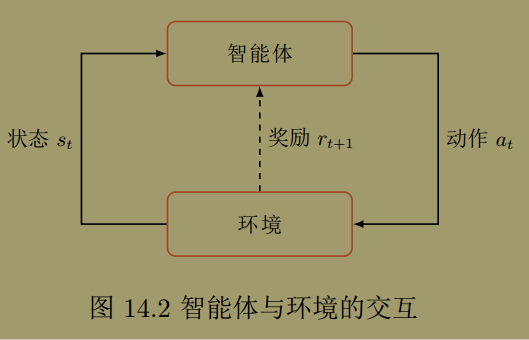
在强化学习中包含两个基本组成部分:
- Agent 或 Actor(智能体): 内部有一个大脑叫策略 $\pi_{\theta}(a \mid s)$ , 是指智能体看到某状态 $s$ 后,采取行动 $a$ 的概率。
- Env (环境): 与智能体交互,用马尔科夫概率建模,$p(s^{\prime} \mid s,\, a)$, 表示环境在当前状态为 $s$, 智能体动作为 $a$ 情况,下一步状态为 $s^{\prime}$ 的概率;此外,环境还反馈给智能体一个即时奖励 $r(s,\, a)$ .
上述策略是随机性策略,给出的是每个动作的概率,另外一种是确定性策略,直接给出从状态到动作的映射表。由于随机性策略能更好的探索环境,因此,一般采用随机性策略。
目标函数
强化学习的目标函数是 总的奖励的期望 最大。
以玩电子游戏为例,游戏主机就是环境,游戏画面就是状态,人就是智能体,人走的每一步就是一个动作,每一步的得分就是奖励,目标是使得最终的总奖励最大。
这一过程可以看作是马尔科夫过程。
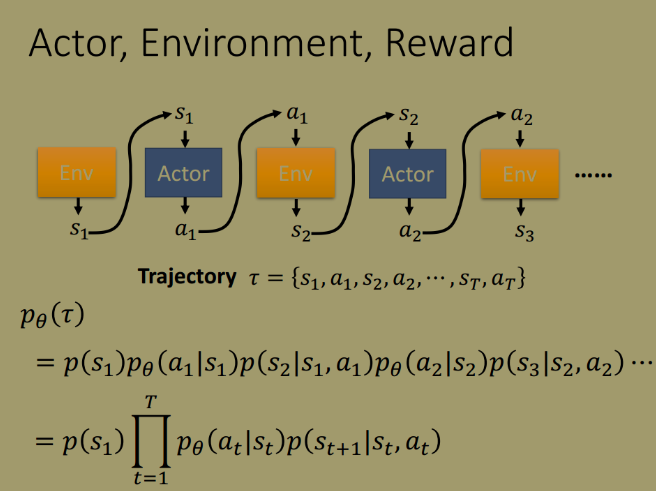
期望奖励为:
理论上,在求解期望奖励时要遍历所有的轨迹 $\tau$ , 但是其数目往往是不可列举的,因此,采用抽样取平均值的方法作为期望的估计值。
值函数
为了估计期望奖励,定义了 状态值函数 和 状态-动作值函数。
状态值函数 $V^{\pi}(s)$ 是指从状态 $s$ 出发执行策略 $\pi$ , 得到的期望总奖励;状态-动作值函数 $Q^{\pi}(s, a)$ 是指从状态 $s$ 出发,经过动作 $a$, 再执行策略 $\pi$ 得到的期望总奖励。状态值函数与状态-动作值函数之间存在以下关系,状态-动作值函数又叫 $Q$ 函数
其中, $\gamma$ 是折扣率
另一个重要的方程是 贝尔曼方程,状态值函数和 Q 函数都有贝尔曼方程,描述当前状态的值函数可以通过下一个状态的值函数计算得到。
状态值函数的贝尔曼方程:
Q 函数的贝尔曼方程:
值函数的作用,如果 $Q^{\pi}(s,a)>V^{\pi}(s)$, 则表示在状态 $s$ 下,执行动作 $a$ 比直接按策略执行要好,因此,可以调整策略 的参数,使得 $\pi(a\mid s)$ 的概率增加。
以下提到“值函数”专指状态值函数
深度强化学习
传统的强化学习一般是解决状态和动作都是离散且有限的问题,可以用表格记录优化过程数据,用类似动态规划的方法求解。但是,对于连续问题和状态和动作巨多的离散问题,传统的强化学习是无能为力。
深度强化学习( deep reinforcement learning)是将强化学习和深度学习结合在一起,用强化学习来定义问题和优化目标,用深度学习来解决策略和值函数的建模问题,然后用反向传播算方法优化目标函数。
模型分类
- 基于值函数的方法:基于值函数的学习方法中,策略一般为确定性的策略。策略优化通常都依赖于值函数,关键在于估计值函数
- 动态规划(模型已知情况下,即环境的状态转移概率可以获得)
- Q-Learning
- SARSA
- 基于策略函数的方法:一种直接的方法是在策略空间直接搜索来得到最佳策略,称为策略搜索 (Policy Search).
- Policy Gradient (REINFORCE)
动态规划
动态规划算法一般适用于状态离散、模型已知的强化学习问题,也是最简单的情形。
具体求解算法分为:
- 策略迭代算法 先进行策略评估迭代,再基于贪心思想策略更新的迭代
- 值迭代算法 根据贝尔曼最优方程,直接进行(最优)值函数迭代,进而得到最优策略
策略迭代
策略迭代是先固定策略,用一个迭代进行策略评估先求值函数,然后基于现有值函数更新策略,以此循环往复,直至收敛。
策略更新是根据 $Q$ 函数按贪心思想确定既定状态下的最佳动作:
算法伪代码:

值迭代
值迭代是利用贝尔曼最优方程同时进行值函数迭代和隐式的策略更新,贝尔曼最优方程:
与贝尔曼方程对比,发现区别在于原来最外层的“期望”运算变成“最大值”运算。
算法伪代码:

Policy Gradient
策略梯度 ( Policy Gradient)是一种基于梯度的强化学习方法。假设 $\pi_{\theta}$ 是一个关于 θ 的连续可微函数,我们可以用梯度上升的方法来优化参数 $\theta$ 使得目标函数 $\bar{R}_{\theta}$ 最大。
对 $\bar{R}_{\theta}$ 求微分得

以分类问题为例,考虑实现问题
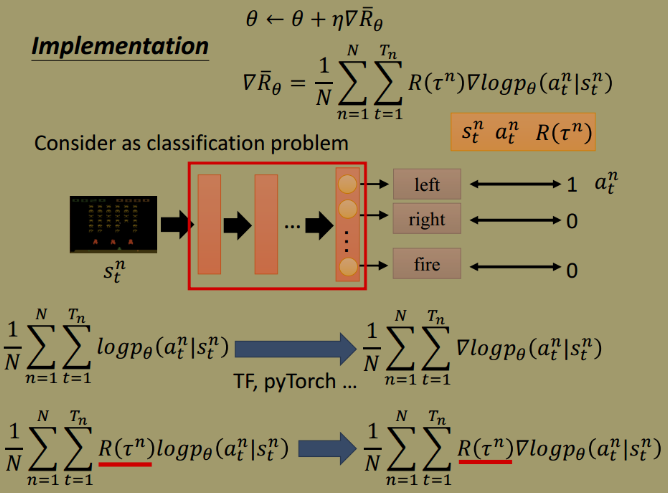
(minimize cross entropy == maximize log likelyhood)
与普通的监督学习不同的是,策略梯度在目标函数前面多乘了一个系数 $R\left(\tau^{n}\right)$, 它表示正常游戏得到的 reward.
Tip 1: Add a Baseline
在某些情况下,reward 可能总是正的,采用策略梯度优化时会使得所有采样到的动作的概率上升,虽然概率的大小取决于 reward 的大小,但是这毕竟是采样,这会造成没有被采样到的动作的概率显著降低,这不是我们所希望的。为解决这种现象,在原来的 reward 上减去一个常数。

Tip 2: Assign suitable credit
用一场游戏总的 reward 作为每个时间点动作的权重也不合适,当前时间点的动作只会对今后的 reward 产生影响,评价当前动作的好坏,可以用今后 reward 的总和,同时考虑时效性的影响。

综合 tip1 和 tip 2,将原来的“权重”用 advantage function 替换,用来衡量采取某一动作的好坏程度。
on-policy vs. off-policy
强化学习可以分为两类:
- on-policy: 智能体学习和与环境交互是同时进行的,采样和更新是同针对一个策略
- off-policy: 智能体学习和与环境交互不是同时进行的,采样和更新分别使用不同策略
如果采用 on-policy 的策略梯度进行学习会有问题,奖励期望的微分公式是
在进行学习前,首先要采集大量的数据,然后与环境进行交互,更新 Actor 参数,但是,一旦更新完参数,轨迹分布将会改变,原来采集的数据将无法利用,必须重新采集数据,效率低,可以通过重要性采样,引入重要性权重来实现对目标策略 $\pi$ 的优化,这就是 off-policy。